ML-Ch6-Decision Trees
[Machine Learning blog series](tags/Machine Learning)
Decision Trees: A Powerful Tool for Machine Learning
Decision trees are versatile machine learning algorithms that can perform both classification and regression tasks, and even multioutput tasks. They are the fundamental components of random forests, which are among the most powerful machine learning algorithms available today.
Training and Visualizing a Decision Tree
To start, we’ll train a decision tree on the well-known Iris dataset and visualize it using Graphviz.
1 | from sklearn.datasets import load_iris |
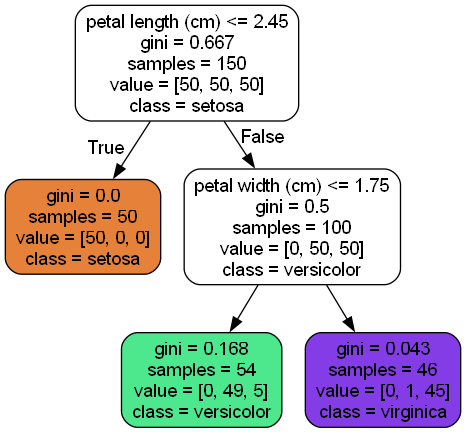
Making Predictions
One of the many qualities of decision trees is that they require very little data preparation. In fact, they don’t require feature scaling or centering at all.
Equation of Gini Impurity:
$$
Gᵢ = 1 − \sum_{k=1}^{n} (pᵢ,ₖ)^2
$$
Note: Scikit-Learn uses the CART algorithm, which produces only binary trees (trees with nodes having exactly two children). Other algorithms, like ID3, can produce trees with nodes that have more than two children.
Model Interpretation: White Box vs Black Box
Decision trees are intuitive and their decisions are easy to interpret. These models are often called white box models. In contrast, random forests and neural networks are generally considered black box models because their decision-making processes are harder to interpret.
The field of interpretable machine learning focuses on creating systems that can explain their decisions in a way that humans can understand. This is especially crucial in domains like healthcare and finance where fairness and accountability are paramount.
The CART Training Algorithm
CART (Classification and Regression Trees) works by splitting the training set into two subsets using a single feature k and a threshold $t_k$. It searches for the pair (k, $t_k$) that produces the purest subsets, weighted by their size. The algorithm then splits the subsets recursively until it reaches the maximum depth. It’s a greedy algorithm.
Gini Impurity vs Entropy?
Both Gini Impurity and Entropy are used to measure impurity in decision trees, but they behave slightly differently. While Gini Impurity is faster to compute, Entropy tends to produce more balanced trees.
Equation of Entropy:
$$
Hᵢ = - \sum_{k=1}^{n} pᵢₖ \log_2(pᵢₖ) \quad \text{where} \quad pᵢₖ \neq 0
$$
When to use Gini Impurity vs Entropy?
- Gini Impurity is generally faster and works well in most cases.
- Entropy tends to produce slightly more balanced trees but can be more computationally intensive.
Regularization Hyperparameters
- Nonparametric models: These models do not have a fixed number of parameters, so they can adapt closely to the data.
- Parametric models: Models like linear regression have predefined parameters, limiting flexibility and reducing overfitting risk.
- Regularization: To avoid overfitting, we need to restrict the decision tree’s flexibility. One common way to do this is by limiting the depth of the tree.
Regression with Decision Trees
Decision trees are also capable of performing regression tasks. Here’s how you can train a decision tree regressor using a quadratic dataset:
1 | import numpy as np |
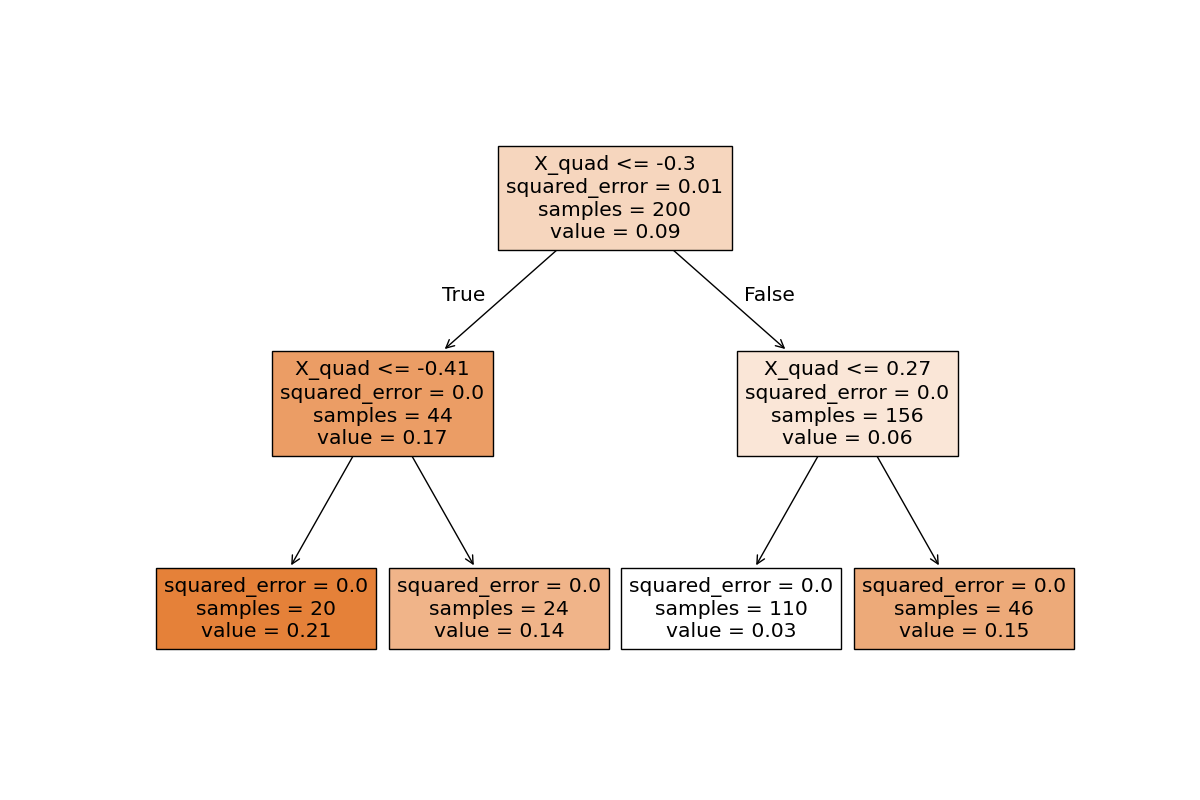
Decision Trees Have a High Variance
The main challenge with decision trees is their high variance. Small changes to the hyperparameters or the data can produce significantly different models. To mitigate this, we can average predictions over many trees, as done in Random Forests.
A random forest is an ensemble of decision trees that reduces variance and is one of the most powerful machine learning models available today.
ML-Ch6-Decision Trees
https://emilypeng2017.github.io/2025/02/09/ML-Ch6-Decision-Trees/



